Integrazione Kubernetes ed F5
Sto maturando in questi ultimi tempi una certa esperienza nella gestione di una infrastuttura basata su Docker e Kubernetes e dopo un periodo di gestazione di circa un anno, confrontandomi con colleghi che lavorano in altre realtà pare sia una tempistica comune, sono arrivato a metterla in produzione e cominciare a installare o adattare le prime applicazioni, traendo talvolta dei notevole vantaggi ed a volte dovendo risolvere problemi inaspettati.
Come sempre dopo la diffidenza e poi la crescente confidenza nella specifica tecnologia, si comincia a volere di più. Lo scenario classico in cui Kubernetes viene deployato prevede alcuni nodi master, preferibilmente in numero dispari e maggiore di tre (la componente critica che richiede queste attenzioni è il backend etcd, essendo basato su quorum) su cui gira Kubernetes, ed un numero sempre crescente di worker, o minion per i nostalgici, su cui girano invece le applicazioni containerizzate. In questo scenario la situazione è la seguente:
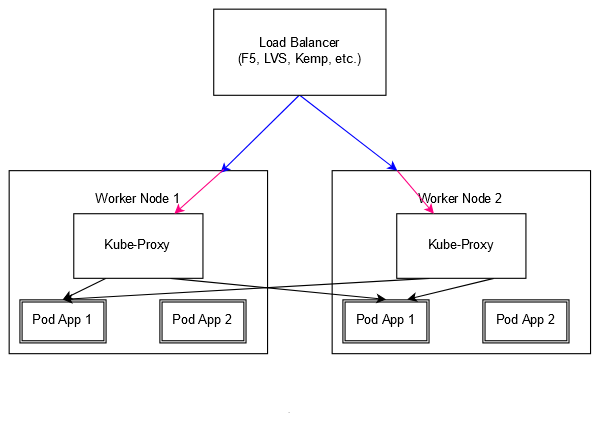
Su ciascun nodo worker è esposta solitamente una porta per ciascun “servizio” (probabilmente una singola applicazione ma anche l’aggregato di più applicazioni tramite un Ingress, assimilabile ad un reverse proxy), questa porta è gestita da kube-proxy che fa da load balancer tra il mondo esterno ed i container della applicazione associata (nel nostro caso App 1), che essi siano su quell’host o su un qualsiasi host. In pratica qualsiasi worker diventa un possibile punto di ingresso per collegarsi alla nostra “App 1”. Volendoci astrarre dal singolo nodo, abbiamo poi bisogno di un bilanciatore, che sia LVS, Kemp o F5, davanti a tutti questi worker in modo tale da poter distribuire il carico di ingresso su tutti i worker e gestire la rottura di un qualsiasi nodo. Quella fatta fino ad ora è una semplificazione, ma è sufficiente per introdurre il tema.
La situazione sopra citata non è affatto male ed è già utilizzata da me con successo, ma ha alcuni limiti ed alcune noie. La prima noia, se ne accorge chiunque entra in questo mondo, è che probabilmente presto le richieste di nuovi servizi potrà esplodere per i seguenti motivi:
- la facilità con cui è possibile, applicativamente parlando, pacchettizzare l’applicazione in formato Docker rendendola indipendente dalle altre fino ad ora sviluppate e non dover invece installarla su un application server comune (che sia IIS, un server PHP, Node o JBoss) dovendone gestire la convivenza
- la tendenza attuale a dividere applicazioni monolitiche in applicazioni – servizi – più piccoli facilmente manutenibili
tutto ciò crea un sacco di attività amministrative che come minimo impattano, oltre che su Kubernetes dove devo definire l’applicazione, il servizio e le risorse che usa, anche Load Balancer, DNS e PKI, a meno di non usare stretegie lazy come il wildcard dns e certificate.
Il limite invece è il fatto che se in una applicazione tradizionale il load balancer F5 vede direttamente l’applicazione sul singolo nodo, quindi ne effettua la verifica tramite Health Check e la esclude singolarmente, in questo contesto il balancer è tagliato fuori e può intervenire solo per bilanciare il bilanciatore (Kube-Proxy) dei container. Overhead da una parte, minor controllo dall’altra facendo in pratica due volte lo stesso lavoro, con la scomodità di dover configurare in maniera fantasiosa lo stikyness delle sessioni, che F5 gestirebbe egregiamente dal suo lato.
Qui ci viene in aiuto l’integrazione tra F5 e Kubernetes perché il Load Balancer non è più spettatore esterno di quel che succede all’interno del mondo containerizzato, ma vede direttamente i container e quindi è possibile sfruttare la maturità delle funzioni di bilanciamento, persistenza ed offloading. Ci sono dei prerequisiti per poter sfruttare questa integrazione:
- il primo è disporre di una licenza che preveda il supporto SDN, cioè Software Defined Networks, per permettere la configurazione del tunnel VXLAN; nel mio caso ho utilizzato una licenza developer e quindi ero già perfettamente coperto
- il secondo è di utilizzare per le overlay network flannel o simili (ad esempio Canal, che comprende sia Calico che Flannel) configurato per utilizzare le VXLAN; è previsto anche il supporto BGP ma non mi sono interessato
Lo schema che si va a realizzare è il seguente:
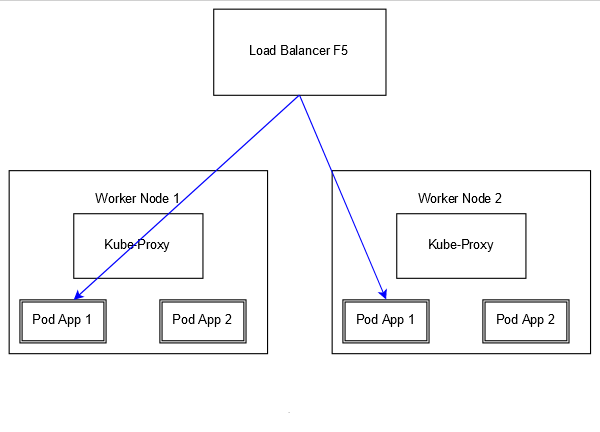
Come fa l’F5 a contattare direttamente i Pod? Per farlo prende parte alla overlay network utilizzata dai Pod e dai nodi per comunicare tra loro. Flannel, uno dei più utilizzati supporti di rete su Kubernetes, non fa altro che creare una rete virtuale tra gli host in modo tale da assegnare, per ciascun Pod (quindi container in esecuzione), un IP su questa rete e permettere ai Pod di vedersi direttamente tra loro; questo è il modo con cui Kube-Proxy configura o realizza il bilanciamento di Pod all’interno o all’esterno dell’host. Quello che si va a realizzare in realtà è quindi una cosa del genere:
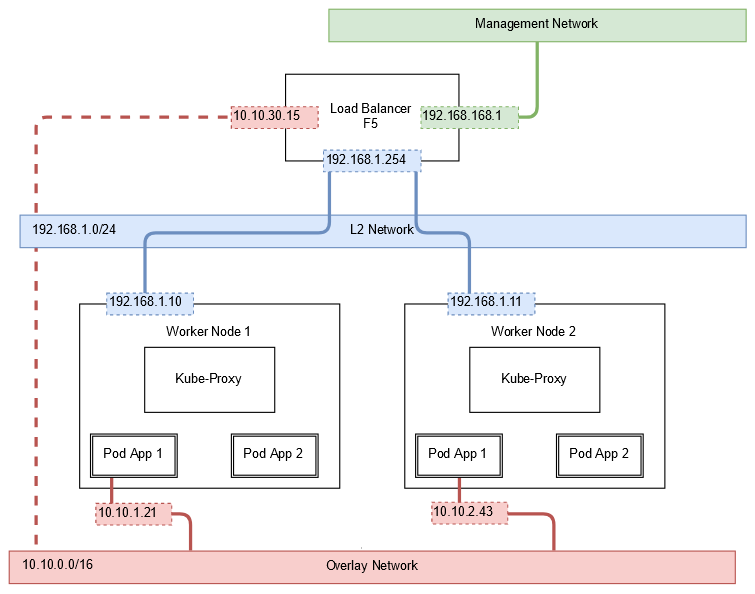
Dando i nomi alle cose, vediamo che l’F5 ha una sua interfaccia di rete sulla rete L2 che connette tra loro gli host; questi, tramite flannel, hanno una interfaccia di rete virtuale sulla overlay network, rete ampia (solitamente una classe B) su cui sono installati i POD. Ciascun host per semplicità gestisce una intera classe C (es. 10.10.1.0/24 sul worker node 1, 10.10.2.0/24 sul worker node 2) ed ha una interfaccia di rete flannel su questa rete, il tutto gestito in autonomia dall’agent flannel (il plugin CNI, Container Network Interface) che registra queste informazioni “su Kubernetes”. Ogni volta che aggiungo un worker, viene assegnata una nuova classe C libera e viene detto a tutti i nodi che qualora si voglia raggiungere quella rete, si dovrà contattare il nuovo nodo nella rete VXLAN. Se prendiamo ad esempio Worker 1:
angeloxx@node01:~$ kubectl describe node node01Name: node01Roles: masterLabels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux kubernetes.io/hostname=node01 node-role.kubernetes.io/master=Annotations: flannel.alpha.coreos.com/backend-data={"VtepMAC":"ea:f9:46:be:69:41"} flannel.alpha.coreos.com/backend-type=vxlan flannel.alpha.coreos.com/kube-subnet-manager=true flannel.alpha.coreos.com/public-ip=192.168.1.10 node.alpha.kubernetes.io/ttl=0 volumes.kubernetes.io/controller-managed-attach-detach=true[...]PodCIDR: 10.10.1.0/24 |
La prima cosa da fare quindi configurare su F5 una interfaccia su questa VXLAN creando prima la definizione del tunnel:
create net tunnels vxlan fl-vxlan port 8472 flooding-type nonecreate net tunnels tunnel flannel_vxlan key 1 profile fl-vxlan local-address 192.168.1.254 |
e poi configurando, su questa nuova interfaccia dell’F5, un SelfIP sulla rete flannel che andremo ad assegnare poi anche su Kubernetes, ad esempio 10.10.30.15 sulla classe C 10.10.30.0/24 e quindi:
tmsh create net self 10.10.30.15/16 allow-service all vlan flannel_vxlantmsh save sys config |
rileviamo il mac-address che ha l’interfaccia flannel_vxlan in modo da riutilizzarla poco dopo:
tmsh show net tunnels tunnel flannel_vxlan all-properties-------------------------------------------------Net::Tunnel: flannel_vxlan-------------------------------------------------MAC Address ab:12:cd:34:ef:56 |
Informiamo poi Kubernetes della nostra scelta creando un nodo fittizio alla rete flannel che rappresenti l’interfaccia virtuale dell’F5:
angeloxx@node01:~$ cat <<\EOF | kubectl apply -f -apiVersion: v1kind: Nodemetadata: name: bigip annotations: # Provide the MAC address of the BIG-IP VXLAN tunnel flannel.alpha.coreos.com/backend-data: '{"VtepMAC":"ab:12:cd:34:ef:56"}' flannel.alpha.coreos.com/backend-type: "vxlan" flannel.alpha.coreos.com/kube-subnet-manager: "true" # Provide the IP address you assigned as the BIG-IP VTEP flannel.alpha.coreos.com/public-ip: 192.168.1.254spec: # Define the flannel subnet you want to assign to the BIG-IP device. # Be sure this subnet does not collide with any other Nodes' subnets. podCIDR: 10.10.30.0/24EOF |
L’errore che io ho fatto a questo punto è quello di credere che i nodi possano già pingare l’F5, ma in verità l’F5 non è informato di quali siano gli altri endpoint della rete flannel ed è qui che entra in gioco il controller F5. Il produttore infatti mette a disposizione due applicazioni docker, un “controller” ed un sostituto del kube-proxy (non più necessario dalla versione 1.4 dell’integrazione) fornito da Kubernetes. Il primo tra i suoi molti compiti ha anche quello di aggiornare tunnel static forwarding table dell’F5 e indicare quali siano gli altri endpoint.
Si installa quindi lo snippet fornito da F5, personalizzando (qui è semplificato e non si è passati da una Secret) per lo meno l’IP di management dell’F5, username, password, la modalità di integrazione (detta cluster) e l’interfaccia tunnel utilizzata per questo cluster, ipotizzando infatti che questo F5 serva altri cluster nel medesimo modo. E’ necessario anche creare su F5 ed indicare qui una partizione, perché volutamente questa integrazione non può agire sulla partizione /Common:
angeloxx@node01:~$ kubectl create serviceaccount bigip-ctlr -n kube-systemangeloxx@node01:~$ cat <<\EOF | kubectl apply -f -kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1beta1metadata: name: bigip-ctlr-clusterrolerules:- apiGroups: - "" - "extensions" resources: - nodes - services - endpoints - namespaces - ingresses - secrets - pods verbs: - get - list - watch- apiGroups: - "" - "extensions" resources: - configmaps - events - ingresses/status verbs: - get - list - watch - update - create - patch---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1beta1metadata: name: bigip-ctlr-clusterrole-binding namespace: kube-systemroleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: bigip-ctlr-clusterrolesubjects:- kind: ServiceAccount name: bigip-ctlr namespace: kube-systemEOFangeloxx@node01:~$ cat <<\EOF | kubectl apply -f -apiVersion: extensions/v1beta1kind: Deploymentmetadata: name: k8s-bigip-ctlr-deployment namespace: kube-systemspec: replicas: 1 template: metadata: name: k8s-bigip-ctlr labels: app: k8s-bigip-ctlr spec: serviceAccountName: bigip-ctlr containers: - name: k8s-bigip-ctlr # replace the version as needed image: "f5networks/k8s-bigip-ctlr:1.4.0" env: - name: BIGIP_USERNAME value: admin - name: BIGIP_PASSWORD value: admin command: ["/app/bin/k8s-bigip-ctlr"] args: [ "--bigip-username=$(BIGIP_USERNAME)", "--bigip-password=$(BIGIP_PASSWORD)", "--bigip-url=192.168.168.1", "--bigip-partition=kubernetes", "--pool-member-type=cluster", "--flannel-name=flannel_vxlan" "--resolve-ingress-name=LOOKUP" ]EOF |
sufficiente per fare in modo che l’F5 ora sia cosciente del fatto che esistono altri nodi sulla rete flannel e sappia come contattarli
tmsh show net fdb tunnel-----------------------------------------------------------------------Net::FDBTunnel Mac Address Member Dynamic-----------------------------------------------------------------------flannel_vlan ea:f9:46:be:69:41 endpoint:192.168.1.10%0 noflannel_vlan 56:58:a2:55:fc:b4 endpoint:192.168.1.11%0 no |
da ora sarà quindi pingabile il 10.10.30.15 da tutti i nodi. Con l’ultima versione dell’integrazione, la 1.4.0, qualcosa è cambiato perché non è più necessario sostituire il kube-proxy fornito Kubernetes con uno fornito da F5, semplificando e standardizzando l’integrazione visto che ad ogni aggiornamento il kube-proxy sarebbe stato ri-aggiornato alla versione Kubernetes.
Partiamo ora da una applicazione generica da bianciare con F5, ad esempio un hello world in ascolto sulla 9000 (avendo un cluster misto con nodi Windows e Linux è necessario specificare il nodeSelector):
angeloxx@node01:~$ cat <<\EOF | kubectl apply -f -apiVersion: apps/v1kind: Deploymentmetadata: name: hello-world-deployment labels: app: hello-worldspec: replicas: 3 selector: matchLabels: app: hello-world template: spec: nodeSelector: beta.kubernetes.io/os: linux metadata: labels: app: hello-world spec: containers: - name: hello-world image: psitrax/hello-world ports: - containerPort: 9000EOF |
l’applicazione se contattata ci riporta anche il REMOTE_ADDR e l’HTTP_HOST in modo da poter verificare il corretto bilanciamento. Creiamo poi un Service a cui non assegnamo ne un NodePort (cioè una porta esposta su ciascun nodo) ne un ClusterIP (quindi un bilanciatore interno alla rete Kubernetes accessibile da un VIP), quindi una semplice entry a DNS che elenchi tutti i Pod attivi e Ready detta Headless:
angeloxx@node01:~$ cat <<\EOF | kubectl apply -f -kind: ServiceapiVersion: v1metadata: name: hello-world-svcspec: selector: app: hello-world ports: - name: http protocol: TCP port: 9000 targetPort: 9000 sessionAffinity: None clusterIP: NoneEOF |
che immediatamente configura come endpoint tutti i Pod attualmente attivi per l’applicazione hello-world:
angeloxx@node01:~$ kubectl describe service hello-world-svcName: hello-world-svcNamespace: defaultLabels: <none>Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"hello-world-svc","namespace":"default"},"spec":{"clusterIP":"None","ports":[{"...Selector: app=hello-worldType: ClusterIPIP: NonePort: http 9000/TCPTargetPort: 9000/TCPEndpoints: 10.10.0.19:9000,10.10.0.20:9000,10.10.3.3:9000Session Affinity: NoneEvents: <none> |
Ora è possibile configurare un VirtualServer su F5 definendolo su Kubernetes come:
apiVersion: extensions/v1beta1kind: Ingressmetadata: name: vs-01 namespace: default annotations: kubernetes.io/ingress.class="f5" virtual-server.f5.com/ip: "192.168.1.250" virtual-server.f5.com/http-port="80" virtual-server.f5.com/partition: "kubernetes" virtual-server.f5.com/balance="round-robin" virtual-server.f5.com/health: | [ { "path": "/", "send": "HTTP GET /", "interval": 5, "timeout": 10 } ]spec: backend: # The name of the Service you want to expose to external traffic serviceName: hello-world-svc servicePort: 9000 |
Mentre nelle versioni precedenti era necessario definire il VirtualServer con una notazione JSON del tutto estranea agli oggetti Kubernetes (cosa ancora supportata per esigenze non HTTP):
kind: ConfigMapapiVersion: v1metadata: name: vs-01 namespace: default labels: f5type: virtual-serverdata: schema: "f5schemadb://bigip-virtual-server_v0.1.7.json" data: | { "virtualServer": { "frontend": { "balance": "round-robin", "mode": "http", "partition": "kubernetes", "virtualAddress": { "bindAddr": "192.168.1.250", "port": 80 }, "sslProfile": { "f5ProfileName": "Common/testcert" } }, "backend": { "serviceName": "hello-world-svc", "servicePort": 9000 } } } |
ora l’F5 agisce come Ingress controller e quindi configura, tramite apposite annotations, tutte la caratteristiche tipiche dei questo oggetto come la partizione, il tipo di bilanciamento, la porta e l’IP associati e come backend, come in un qualsiasi Ingress, l’oggetto service precedentemente configurato.
Quel che succede è che su F5 verrà configurato, e continuamente aggiornato, un Virtual Server con l’IP indicato, associato ad un pool di server che riporterà direttamente gli IP dei Pod; ad ogni cambio di stato dei container associati al service la configurazione del pool verrà aggiornata con i nuovi nodi. L’healthcheck definito a livello di VirtualServer si sommerà a quello eventualmente configurato a livello di Pod; in caso di fallimento nel primo caso il pool-node verrà marcato come down, nel secondo sarà eliminato dalla lista dei nodi perché rimosso dagli endpoint del Service Kubernetes.
Concludo dicendo che la soluzione è molto comoda per tante ragioni: da una parte è possibile sfruttare le funzionalità offerte da F5 in termini di gestione della persistenza, senza dover inserire un componente aggiuntivo che lo faccia (solitamente un Ngnix configurato come ingress controller), oltre a poter automatizzare tutta la parte di provisioning dei VS. Dall’altra però questa soluzione non appare ancora pronta per la produzione, basti pensare al cambio di rotta nel come l’integrazione è realizzata (inizialmente sostituendo il kube-proxy), al fatto che fino ad un paio di versioni fa un heathcheck fosse configurabile solo nel contenuto inviato al node ma non per la verifica della risposta ed infine l’impossibilità di configurare tutti gli aspetti di un Virtual Server o di un Pool. L’implementazione maturerà, il poter configurare tutto in un unico punto e strumento (applicazione tramite il deployment, load balancer tramite service e ingress, senza ricorrere ad altri tool come Ansible) merita davvero l’impegno necessario al primo setup, quindi se si ha a disposizione un F5 e le licenze necessarie, si può cominciare a lavorarci e se le proprie necessità sono coperte dell’attuale implementazione, provarlo negli ambienti non produttivi.
Riferimenti: